Designing an Architecture for StreetSmart
During a 2025 climate-tech fellowship through Climatebase, I led the technical side of StreetSmart, a digital platform that turns street images into usable insight for cities. Built in close collaboration with urban planner Reena Mahajan and a multidisciplinary team of designers and engineers, the platform makes everyday street experience legible, identifying what makes a street work, or not, for the people it's meant to serve.
 A person uploads a picture of a street and our app shows parts of the street design that make it good or bad to walk around/live in. Email me if you want to join the private beta!
A person uploads a picture of a street and our app shows parts of the street design that make it good or bad to walk around/live in. Email me if you want to join the private beta!
In what mostly amounted to a three-month sprint from product conception to demo day, I led a small global team of software engineers to design and build our AI-powered MVP in collaboration with urban planners. It was successful by most measures: we formalized urban planners' notions of a liveable street, made a working prototype, ran two pilots with partners in India, and are now attracting a fresh batch of volunteers for ongoing development.
I'm continuing on as an advisor, and wanted to write down three architectural decisions that shaped the codebase while they're still fresh:
- Use tech that the team knows
- Maintain a $0/yr annual budget
- Don't blindly trust an LLM
Context: What we built
From the outset, our MVP was to build an app where people could take a picture of a street and the app would call out aspects of the street's design that make it good and bad for liveability/walkability. We chose to build this as more of a small, loveable, correct app rather than as the shell of an enterprise application with a lot of dead ends.
We worked with a team of urban planners and architects to articulate concretely what aspects of the street's design influence liveability/walkability. This team still has many quibbles with what our app recommends, but on the whole think it gets people to notice and think more carefully about their living environment.
The app is designed to work on desktop and mobile. Mobile because we assumed that's where most users would use it, desktop because we needed to test and build it on our computers.
Decision 1: Use tech that the team knows
As a volunteer group, we were limited to whatever people could be inspired to contribute. Which, between working other jobs/school/job hunting, was limited.
We settled on a doacracy mindset, where people who do work have a strong influence on how the work is done. In practice, I'd scope out a component — what it could do and how it might deploy — and a contributor would be responsible for vetting those assumptions and delivering something the project would find useful. I'd then integrate their work into the main app.
We decided that we'd make a web app. The team had a lot of AI-focused data people on it and most of their experience (and most AI tooling) were in Python, so we opted to use that as our backend rather than a more trendy Node.js/Typescript.
Overall, this structure worked reasonably well and left us with these architectural choices:
- a backend FastAPI microservices architecture (which was new to me) because one prolific contributor wrote a working draft of it and coached the rest of the team through deploying and supporting it to production
- vanilla JS on the front-end (not React) because I had extensive experience in vanilla JS, saw little benefit to the complexity of the big frameworks, and others who attempted to build on other stacks were unable to integrate with our existing tech assets
- lots of business logic in vanilla JS because the author had the most experience in it. We appreciated the low-cost in-browser testing where I could set up some flags for the page, edit the file, and then see my results in milliseconds after reloading the page. Another urban planner also learned how to edit these JS business rules and could use the already-installed Chrome Developer Tools to see the results of their changes.
In retrospect this led to some unfortunate outcomes:
- by using vanilla JS rather than React, we may have limited our pool of contributors. The gap between our stack and what many developers used created friction: some contributors with deep React experience found it hard to transfer their patterns to vanilla JS, and others hoping to build React experience weren't motivated by the work. This led to a contingent investing hours in planning a React rewrite that never materialized into code (if only we'd been able to channel that energy into more incremental experiments). Similarly, a graphic designer spent hours vibe-coding a beautiful version of the frontend in Loveable, but we were only able to include it after painstakingly reverse-engineering small parts because the Loveable stack didn't work with what we'd already built.
- by not being good at deploying Python we failed to integrate a privacy-focused contribution that required a different sub-version of Python. If only I had realized virtual environments could come to our rescue.
- having key parts of our business logic written in JS made it hard for contributors with only Python experience to understand what was happening and effectively contribute
Decision 2: Maintain a $0/yr annual budget
The AI startup ecosystem is full of free trial offers. But free trials have two relevant periods: the free period, and then the paid period.
I had an intuition that the transition to the paid period of too many products would introduce uncomfortable questions for the project. I had no doubts that the founder was bought in to the success of the project, but I knew she had real financial constraints. Could she indefinitely invest $1/mo in the project? Probably. $100/mo? Probably not without a clear path to revenue.
Should we have signed up for these trials, we would have also had a lot more management overhead: Whose credit card would be on the trial? Does it matter whether the payer is in Europe, India, or the US? Who would keep track of how much we're spending or on track to spend? How did we avoid unbounded spending like people sometimes experience with AWS? Who would be in charge of winding down the service at the end of the free trial, and who would decide that when? Lots of questions, so few great answers.
I also quietly expected that the end of major trial periods would prompt a reckoning for the project: if it wasn't making tangible progress, our product would be unceremoniously shut down and future teams would be forced to start with scratch (or, rather, a bunch of low-quality code and some sketchy instructions about how to run it... which is pretty close to scratch). Conversely, if we were on free-forever plans, the project could lie dormant for a while without it prompting these sorts of shut-down decisions. It was also advantageous for the team, because I suspected some of us might want to use it as a portfolio piece, and it's more engaging to have a working product than a bunch of screenshots.
If we could keep it to $0/yr, lots of problems went away.
How we did it
Indeed, we managed to keep our infrastructure costs very low! Our only ongoing cost is $12/year for the internet domain, which I think is a pretty unavoidable expense. It's also one that makes sense as long as the project lives as a twinkle in the founder's eye, and can survive through several technical architecture changes.
We found acceptable free tiers of products:
- Cloudflare Pages hosts the front-end code. It does it on a CDN close to the user, allowing fast page loads even if our API is a bit slow.
- a free ARM VPS on Oracle Cloud hosts the Python backend, a local mask2former-based image segmenter, a PostgreSQL instance and stores our user-submitted photos
- Google Gemini offered a few hundred calls per day for free, powering much of our more complex logic. Informal suggesting found that Gemini offered similar results to Claude or ChatGPT
- GitHub's free tier handles a lot of our CI and collaboration
Sticking to the free tier gave us a few constraints:
-
Probably staying away from AWS was a good choice, although we may have been able to attract someone who had more experience administering AWS than I did with running a bare Linux server.
-
One downside of the free Gemini was our requests would fail when the Gemini infrastructure was overloaded. And unfortunately it often seemed overloaded while the technical Americans were awake and the urban planning Europeans were awake. Due to mediocre error reporting, this lead non-technical team members to thinking that something was wrong with our app when we could do little about it other than paying more. It eventually got bad enough that a tech person decided to fix it temporarily by paying for Gemini (with some strict cost controls) to keep the app working for our pilot events. Going forward we may re-investigate Gemini's free tier or look around at other models.
-
it mostly closed the door to training a custom model to recognize different parts of street design. Probably this kept us focused on articulating what we want, but it's possible that some model tuning could have gotten us better results.
Decision 3: Don't blindly trust the LLM
There was a stage of development where some of the tech team thought we could make the app work with just an LLM prompt with the response piped back to the user. We never tried this because of three concerns:
- the urban planners (in particular) worried that blind trust in an LLM would reproduce/amplify existing biases in how streets are understood
- I assumed that it would get us to a middling quality level, but then we would have things we wanted to change and we wouldn't have a ton of control over the system and as a result wouldn't have a great way to influence the outcomes.
- mid-2025 LLMs weren't consistently great at making internally consistent outputs, so some application code helps ensure that our final analysis was consistent and avoids embarrassing outcomes from a poisoned input or a model provider having a bad day.
As a result, our final analysis has three layers. In the order that we built them (and that they often execute):
First model: panoptic mask2former
This is the same sort of computer vision model that is designed to power a self-driving car: it labels different parts of the street while also separating different objects from each other (so, for example, you get 2 different pole objects for different poles).
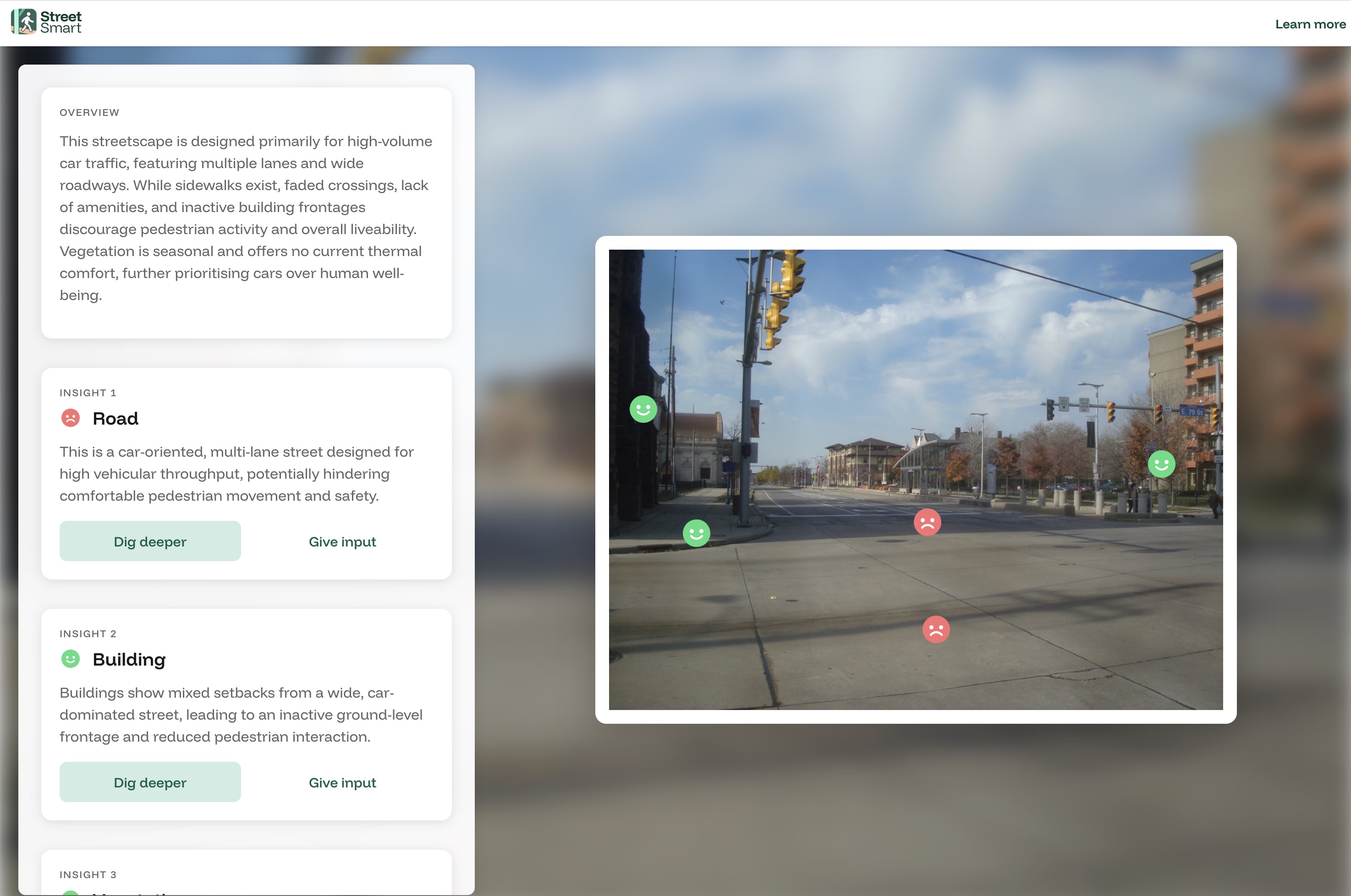
We started visualizing this output in a view like this: the yellow dot is the computed center of each object, and then we have a bunch of metadata about what the object is. For the sake of moving quickly, we chose to simplify each object into one point rather than try to cope with the full polygon data that the model computes.
The mask2former piece was the first piece we wrote. We let the team upload their own images and visualize the output in this UI, which was both very motivating for the team and the basis for great conversations.

Next: Gemini LLM
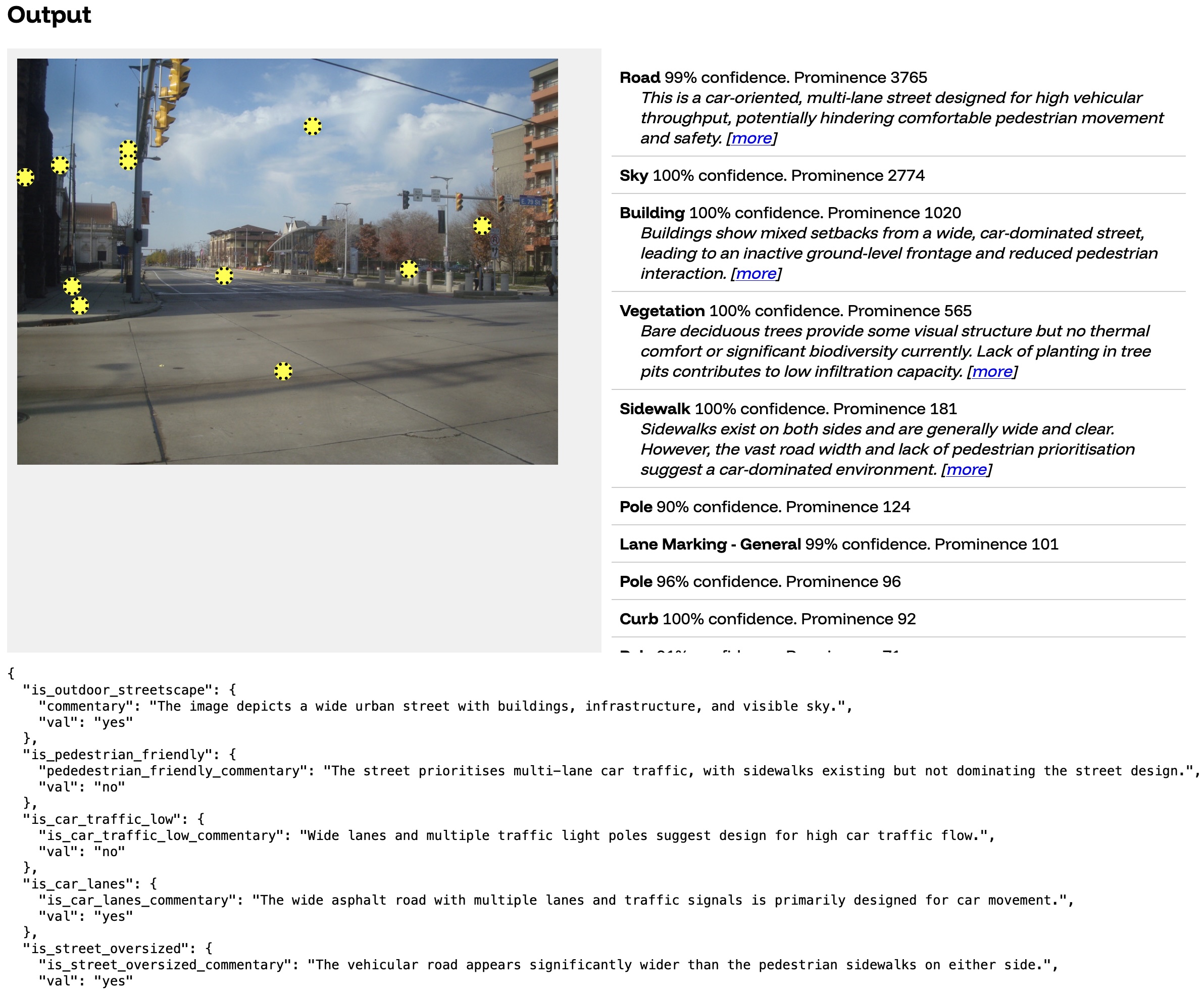
Working with urban planners, we wrote 100+ individual specific questions for an LLM to answer about the picture.
You can see some of the raw output of the LLM at the bottom. That first question (is_outdoor_streetscape) is the result of the prompt "determine if the main subject of the photo is an outdoor streetscape in an urban or suburban setting". In the table you will also see some summaries of different objects. For example, the section we see about the road ("This is a car-oriented...") is the result of us instructing the LLM "In less than 30 words, describe the street type and how it influences pedestrian movement. If car-oriented and applicable, mention a missing crosswalk".
We added some of these rules to our initial output-visualizer, which continued to create great conversations:
Three: Apply rules to stick it together
We apply a set of rules and heuristics to stitch the model outputs into an interactive visualization:
(You can see the interactive version of this example here)
While the Urban team had clear ideas for a more complex version, what we shipped amounted to show the Gemini summary for objects that mask2former recognizes, sorted with the most prominent objects first. Then when the user clicks "dig deeper" use a complex set of rules to figure out which piece of human-written urban educational copy to show.
For this street, StreetSmart calls out a lot of design features that make this street unpleasant to walk around. This is consistent with my memory of this intersection: it was not a pleasant place to walk or be, although it was a fine place to bike or bus through. I guess that's consistent with how the City of Cleveland describes these five miles of this renovated street: a complete street focused on bicycles, bus rapid transit, and car users.
Evaluating this structure
So even though our Gemini prompt contains phrases about the prominent bus stop in the middle of the road like "Despite bus stop shelters, the street lacks visible seating, water fountains, or public toilets for pause" for absence_of_any_street_furniture_utilities, we don't show that because we hadn't reliably found a way to tie that insight to a mask2former element in the picture.
Our current structure forces us to anticipate what will be in the picture and comment on it. When something's not in the picture (like the absence of street furniture), we don't comment on it.
But it also prevents us from making incorrect observations: For example, consider the bike lane on this street. In reality, Euclid Avenue has a bike lane painted on the road, but those lines are pretty faint. Our models tell us different things:
- mask2former identifies a small bike lane (
prominence 27), but it has low confidence in it (39% confidence) - Gemini is confident there is no bike lane, with the
bike_lane_summaryof "Absence of dedicated bike lanes on this wide, multi-lane street discourages cycling"

If we were simply looking at the Gemini output, we might confidently comment on the lack of the bike lane (which is untrue). However, because mask2former sees the bike lane as both very small and of a low confidence, we decide not to talk about it. There is assuredly more nuance we can derive from this kind of mismatch.
In conclusion
If I were starting again, I'd probably make similar core choices: boring tech, $0 infrastructure, strong guardrails on the LLM. What I'd do differently is be clearer to the team that a doacracy means real agency but also real ownership, and make sure everyone was on board with that tradeoff. I'd also reconsider whether tech that was boring to me was also approachable for the average volunteer developer, although I don't know that I should actually have written different code.
A mantra I hear about startups is that what gets you to one step probably won't get you to the next. If StreetSmart's next iteration does something functionally similar, the team will probably want to revisit several architectural decisions. Collecting reliable photo locations probably means shipping native iOS and Android apps. Exposing so much of the app's logic as client-side JS is fine for an MVP but irresponsible for a real tool. And the current backend has no systematic backups or rollback plan to the extent that a few strategic clicks could delete everything: that's a problem.
We made some choices. They got the project to the next step. The coming team will have to decide what gets them to theirs.